

考虑像井字游戏这样的游戏。这个游戏的标准棋盘是一个3×3的网格,玩家轮流放置“X”和“O”符号。第一个连续放置三个符号的玩家获胜。
虽然你可以将棋盘数据存储为9个独立的变量,但我们知道当你有一个元素的多个实例时,最好使用数组
int ttt[9]; // a C-style array of ints (value 0 = empty, 1 = player 1, 2 = player 2)这定义了一个C风格的数组,其中9个元素在内存中按顺序排列。我们可以将这些元素想象成一行值,如下所示
// ttt[0] ttt[1] ttt[2] ttt[3] ttt[4] ttt[5] ttt[6] ttt[7] ttt[8]
数组的维度是选择一个元素所需的索引数量。只包含一个维度的数组称为单维数组或一维数组(有时缩写为1d数组)。上面的ttt就是一维数组的一个例子,因为元素可以用一个索引来选择(例如ttt[2])。
但请注意,我们的一维数组与我们的井字游戏棋盘不太相似,后者存在于两个维度中。我们可以做得更好。
二维数组
在之前的课程中,我们提到数组的元素可以是任何对象类型。这意味着数组的元素类型可以是另一个数组!定义这样的数组很简单
int a[3][5]; // a 3-element array of 5-element arrays of int一个数组的数组称为二维数组(有时缩写为2d数组),因为它有两个下标。
对于二维数组,方便的理解方式是:第一个(左边)下标选择行,第二个(右边)下标选择列。从概念上讲,我们可以将这个二维数组想象成如下排列
// col 0 col 1 col 2 col 3 col 4 // a[0][0] a[0][1] a[0][2] a[0][3] a[0][4] row 0 // a[1][0] a[1][1] a[1][2] a[1][3] a[1][4] row 1 // a[2][0] a[2][1] a[2][2] a[2][3] a[2][4] row 2
要访问二维数组的元素,我们只需使用两个下标
a[2][3] = 7; // a[row][col], where row = 2 and col = 3因此,对于井字游戏棋盘,我们可以像这样定义一个二维数组
int ttt[3][3];现在我们有了一个3×3的元素网格,我们可以使用行和列索引轻松地操作它们!
多维数组
维度多于一个的数组称为多维数组。
C++甚至支持超过2个维度的多维数组
int threedee[4][4][4]; // a 4x4x4 array (an array of 4 arrays of 4 arrays of 4 ints)例如,Minecraft中的地形被划分为16x16x16的方块(称为区块)。
支持更高维度的数组(超过3维),但很少见。
二维数组在内存中的布局方式
内存是线性的(一维的),所以多维数组实际上是作为元素的顺序列表存储的。
以下数组在内存中有两种可能的存储方式
// col 0 col 1 col 2 col 3 col 4
// [0][0] [0][1] [0][2] [0][3] [0][4] row 0
// [1][0] [1][1] [1][2] [1][3] [1][4] row 1
// [2][0] [2][1] [2][2] [2][3] [2][4] row 2C++使用行主序,其中元素按行顺序放置在内存中,从左到右,从上到下
[0][0] [0][1] [0][2] [0][3] [0][4] [1][0] [1][1] [1][2] [1][3] [1][4] [2][0] [2][1] [2][2] [2][3] [2][4]
其他一些语言(如Fortran)使用列主序,元素按列顺序放置在内存中,从上到下,从左到右
[0][0] [1][0] [2][0] [0][1] [1][1] [2][1] [0][2] [1][2] [2][2] [0][3] [1][3] [2][3] [0][4] [1][4] [2][4]
在C++中,初始化数组时,元素以行主序初始化。遍历数组时,以内存中布局的顺序访问元素效率最高。
初始化二维数组
要初始化一个二维数组,最简单的方法是使用嵌套花括号,每组数字代表一行
int array[3][5]
{
{ 1, 2, 3, 4, 5 }, // row 0
{ 6, 7, 8, 9, 10 }, // row 1
{ 11, 12, 13, 14, 15 } // row 2
};尽管有些编译器允许您省略内部花括号,但我们强烈建议您为了可读性而包含它们。
使用内部花括号时,缺失的初始化器将被值初始化
int array[3][5]
{
{ 1, 2 }, // row 0 = 1, 2, 0, 0, 0
{ 6, 7, 8 }, // row 1 = 6, 7, 8, 0, 0
{ 11, 12, 13, 14 } // row 2 = 11, 12, 13, 14, 0
};一个已初始化的多维数组可以省略(仅)最左边的长度规范
int array[][5]
{
{ 1, 2, 3, 4, 5 },
{ 6, 7, 8, 9, 10 },
{ 11, 12, 13, 14, 15 }
};在这种情况下,编译器可以根据初始化器的数量计算出最左边的长度。
不允许省略非最左边的维度
int array[][]
{
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 }
};就像普通数组一样,多维数组仍然可以按如下方式初始化为0
int array[3][5] {};二维数组和循环
对于一维数组,我们可以使用一个循环遍历数组中的所有元素
#include <iostream>
int main()
{
int arr[] { 1, 2, 3, 4, 5 };
// for-loop with index
for (std::size_t i{0}; i < std::size(arr); ++i)
std::cout << arr[i] << ' ';
std::cout << '\n';
// range-based for-loop
for (auto e: arr)
std::cout << e << ' ';
std::cout << '\n';
return 0;
}对于二维数组,我们需要两个循环:一个用于选择行,另一个用于选择列。
有了两个循环,我们还需要确定哪个循环是外层循环,哪个是内层循环。最有效的方法是按照内存中元素的布局顺序访问它们。由于C++使用行主序,因此行选择器应该是外层循环,列选择器应该是内层循环。
#include <iostream>
int main()
{
int arr[3][4] {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }};
// double for-loop with indices
for (std::size_t row{0}; row < std::size(arr); ++row) // std::size(arr) returns the number of rows
{
for (std::size_t col{0}; col < std::size(arr[0]); ++col) // std::size(arr[0]) returns the number of columns
std::cout << arr[row][col] << ' ';
std::cout << '\n';
}
// double range-based for-loop
for (const auto& arow: arr) // get each array row
{
for (const auto& e: arow) // get each element of the row
std::cout << e << ' ';
std::cout << '\n';
}
return 0;
}二维数组示例
让我们看一个二维数组的实际例子
#include <iostream>
int main()
{
constexpr int numRows{ 10 };
constexpr int numCols{ 10 };
// Declare a 10x10 array
int product[numRows][numCols]{};
// Calculate a multiplication table
// We don't need to calc row and col 0 since mult by 0 always is 0
for (std::size_t row{ 1 }; row < numRows; ++row)
{
for (std::size_t col{ 1 }; col < numCols; ++col)
{
product[row][col] = static_cast<int>(row * col);
}
}
for (std::size_t row{ 1 }; row < numRows; ++row)
{
for (std::size_t col{ 1 }; col < numCols; ++col)
{
std::cout << product[row][col] << '\t';
}
std::cout << '\n';
}
return 0;
}这个程序计算并打印所有介于1到9(含)之间的值的乘法表。请注意,在打印表格时,for循环从1而不是0开始。这是为了避免打印第0列和第0行,因为它们都将是0!下面是输出
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81
笛卡尔坐标与数组索引
在几何学中,笛卡尔坐标系常用于描述物体的位置。在二维空间中,我们有两个坐标轴,通常命名为“x”和“y”。“x”是水平轴,“y”是垂直轴。
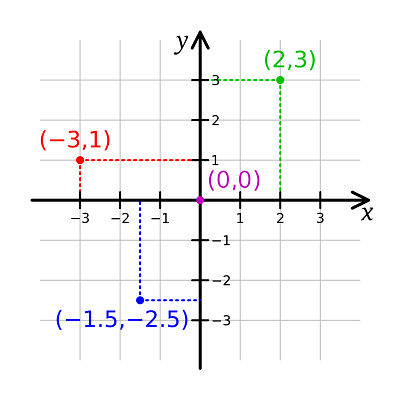
在二维空间中,一个物体的笛卡尔位置可以描述为一个{ x, y }对,其中x坐标和y坐标表示物体相对于x轴向右的距离以及相对于y轴向上的距离。有时y轴是翻转的(因此y坐标描述物体相对于y轴向下的距离)。
现在我们来看看C++中的二维数组布局
// col 0 col 1 col 2 col 3 col 4
// [0][0] [0][1] [0][2] [0][3] [0][4] row 0
// [1][0] [1][1] [1][2] [1][3] [1][4] row 1
// [2][0] [2][1] [2][2] [2][3] [2][4] row 2这也是一个二维坐标系,其中元素的位置可以描述为[row][col](其中col轴被翻转)。
虽然这些坐标系中的每一个都相当容易独立理解,但从笛卡尔{ x, y }转换为数组索引[row][col]有点反直觉。
关键的见解是,笛卡尔系统中的x坐标描述了数组索引系统中正在选择的列。相反,y坐标描述了正在选择的行。因此,一个{ x, y }笛卡尔坐标转换为一个[y][x]数组坐标,这与我们可能预期的相反!
这导致了看起来像这样的二维循环
for (std::size_t y{0}; y < std::size(arr); ++y) // outer loop is rows / y
{
for (std::size_t x{0}; x < std::size(arr[0]); ++x) // inner loop is columns / x
std::cout << arr[y][x] << ' '; // index with y (row) first, then x (col)请注意,在这种情况下,我们将数组索引为a[y][x],这可能与您预期的字母顺序相反。